Exploring more on tree data structures
A helpful guide for anyone interested in learning more about tree data structures, their behavior, and their applications in various fields.
In my earlier article, Understanding Binary Search Trees: A Helpful Guide , I discussed how to make a binary search tree and some of the things you can do with it. In this article, I will look more closely at how this tree data structure behaves.
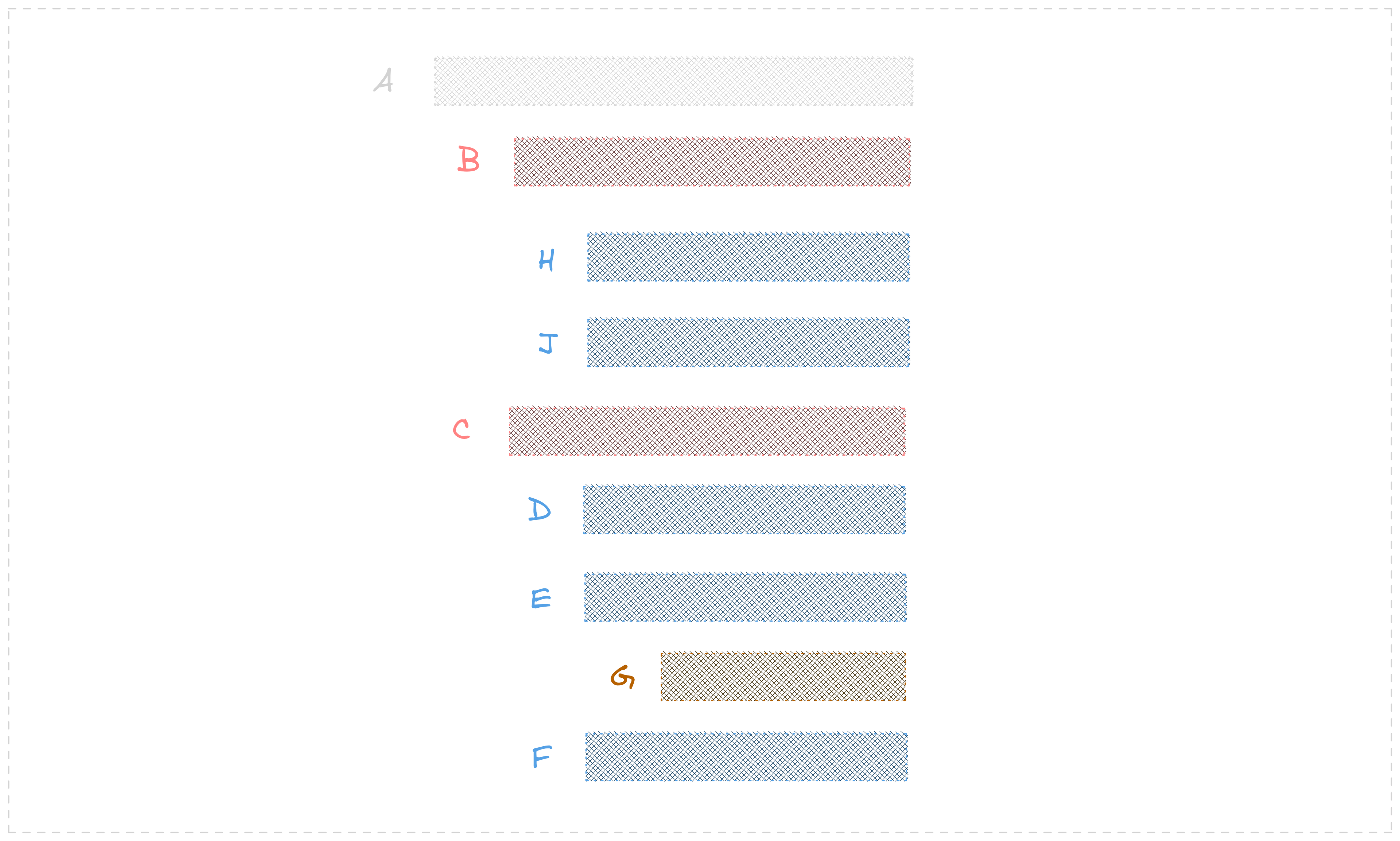
In simple terms, a tree structure is similar to a natural tree, with nodes branching out from one another. Formally, we can define a tree as a finite set T with one or more nodes, and one specifically defined node called the root. The remaining nodes (except), such as T(1), T(2), …, T(n), are called the subtrees of the root.
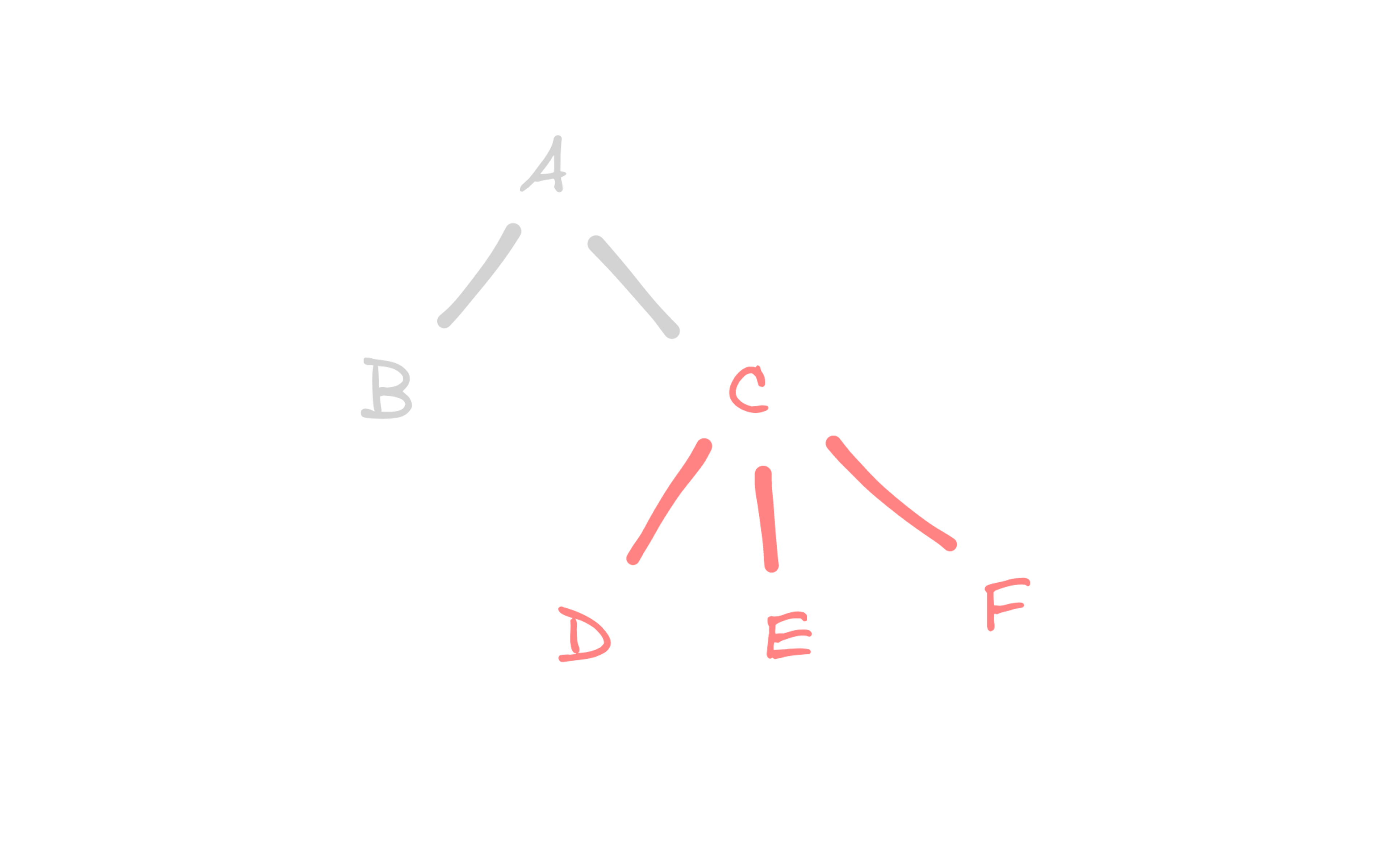
The interesting aspect of the definition of trees is that it can be recursive. That is, a subtree of a tree is itself a tree, with its own root and subtrees. In the given figure, node A is the root of the tree T(A), while node C is the root of the subtree consisting of nodes D, E, and F in the tree T(C). This recursive definition allows us to build complex structures from simple components, much like how we can build complex programs from simple functions.
Levels in trees
In a tree structure, each node has a level, which is determined by how many edges it is away from the root node. The root node is considered to be at level 0, its children are at level 1, its grandchildren are at level 2, and so on. In the given figure, node A is at level 0, its children B and C are at level 1, and the children of C are at level 2. The levels of a tree are important in various tree traversal algorithms. The levels of a tree help us keep track of which nodes we have visited and which ones we have yet to visit, allowing us to perform various operations on the tree according to the desired traversal algorithm.
Trees in family chart
An example of a tree structure is a family generation chart. The chart starts with a single person, usually the oldest known ancestor, as the root node. Each child of the root node represents one of the root node's children, and their children become the root node's grandchildren, forming subtrees. This recursive pattern continues for each subsequent generation, resulting in a complex tree structure that represents a family's lineage.
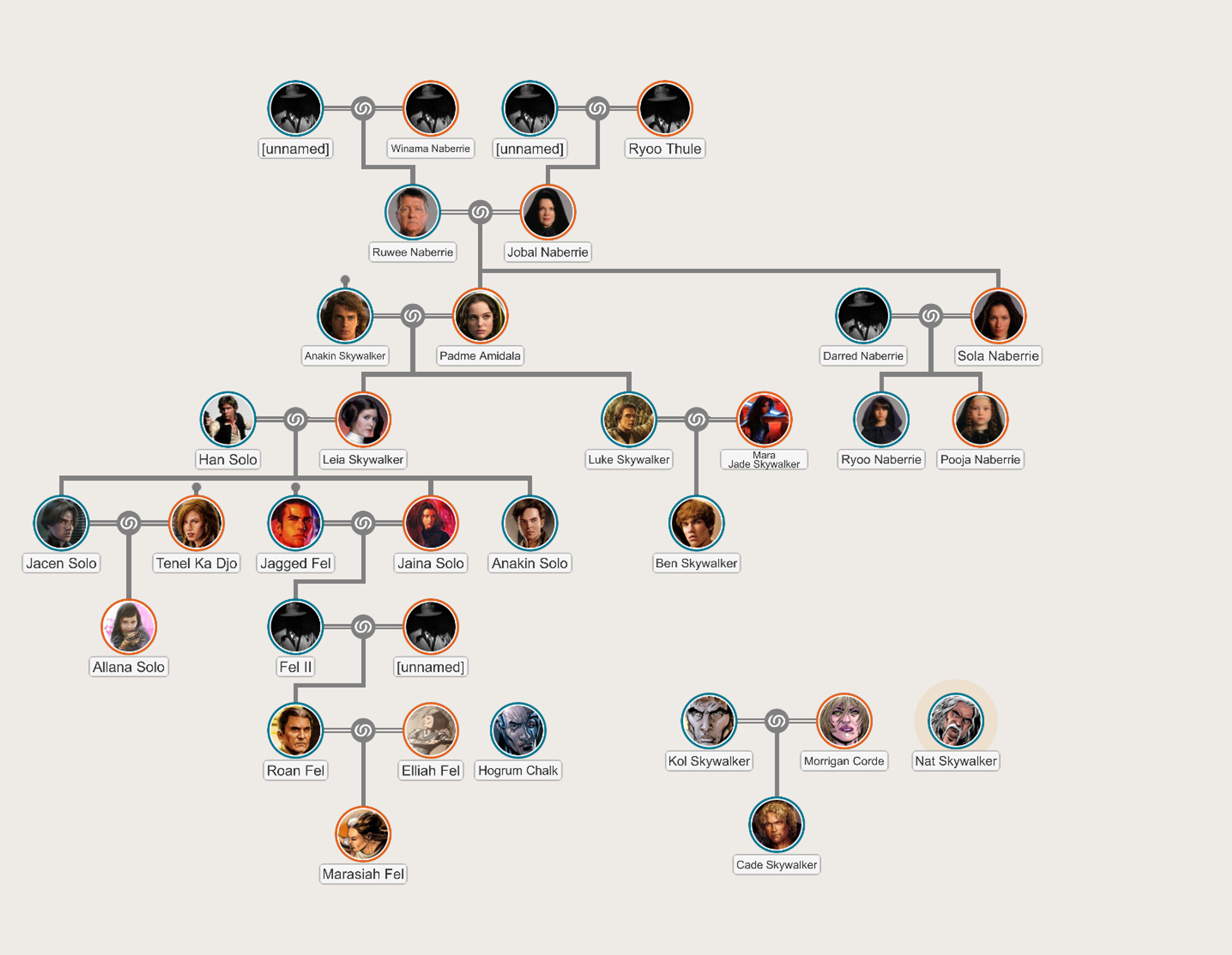
The tree's levels represent generations, with the root node being the first generation and its children being the second, and so on. Tree traversal algorithms can analyze family trees to find relatives, patterns, and relationships. These algorithms can uncover migration patterns, social relationships, and cultural influences.
Sets as trees
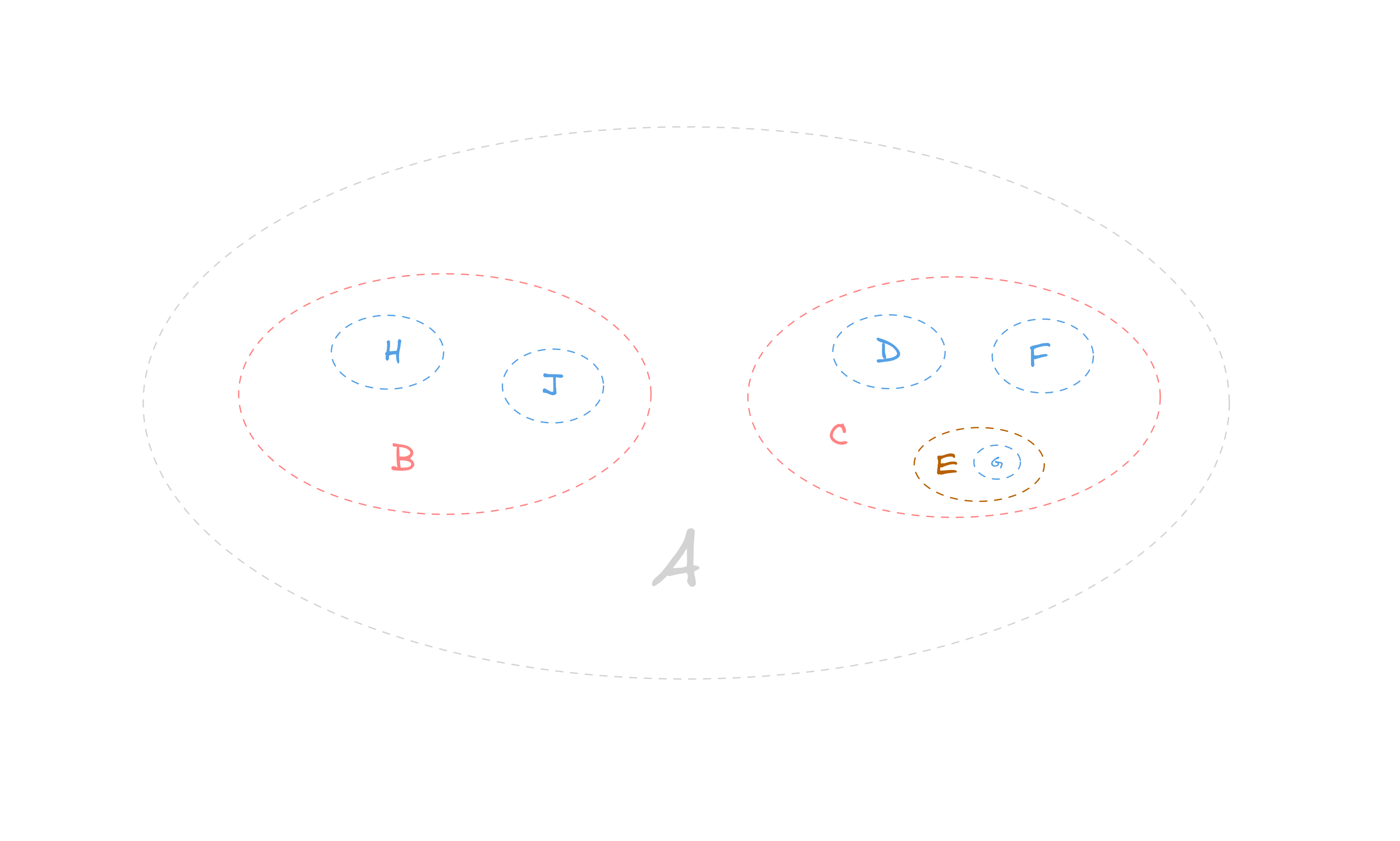
A set is like a tree. Each item in a set has its own spot, like a node in a tree. To combine sets, find their shared items. To find the items that are unique to each set, take them apart and compare them. You can move through a set like you would a tree, using different techniques. The levels of a tree match the subsets of a set. The empty set is at the top and the full set is at the bottom.
Another way to represent tree data structure is by using indentations. A book's table of contents can also be represented as a tree. The book, as a whole, is the root node, while the main chapters are the children. Each chapter can have its own subchapters, creating subtrees. This recursive structure makes it easy for readers to navigate the book and find the information they need. Tree traversal algorithms can be used to analyze the book's structure and identify patterns in the presented information. Any hierarchical classification scheme leads to a tree structure.
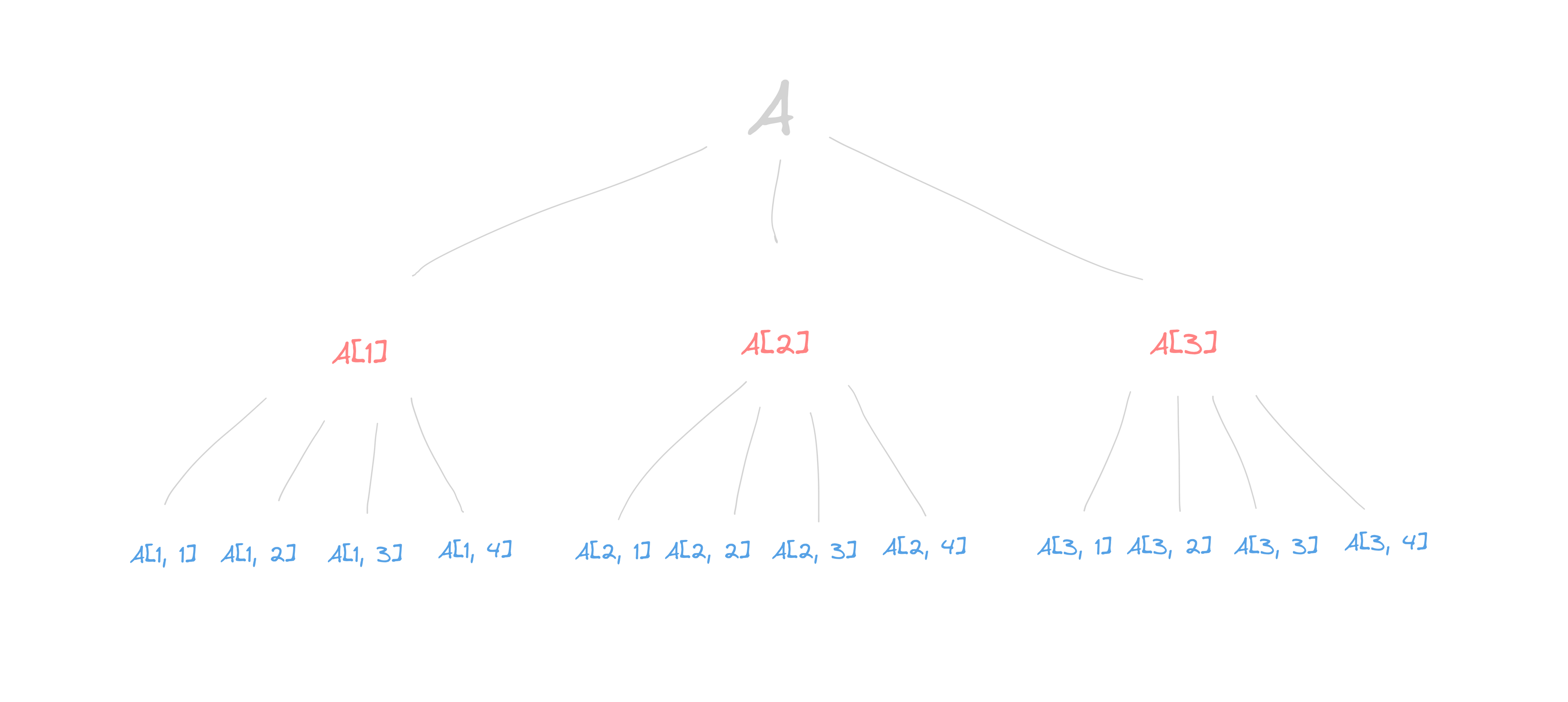
Matrices as trees
A 3x4 matrix can be seen as a tree data structure. Each element in the matrix is a node in the tree. The top row is the root of the tree. The second row has three children. The third row has the grandchildren of the root node, and so on. Trees are also used to represent mazes, where each node is a cell in the maze and each edge is a wall or passage between adjacent cells. Tree traversal algorithms can be used to find a path between two cells, such as a start and finish point. This is useful for solving mazes and can be used in robotics and navigation systems.
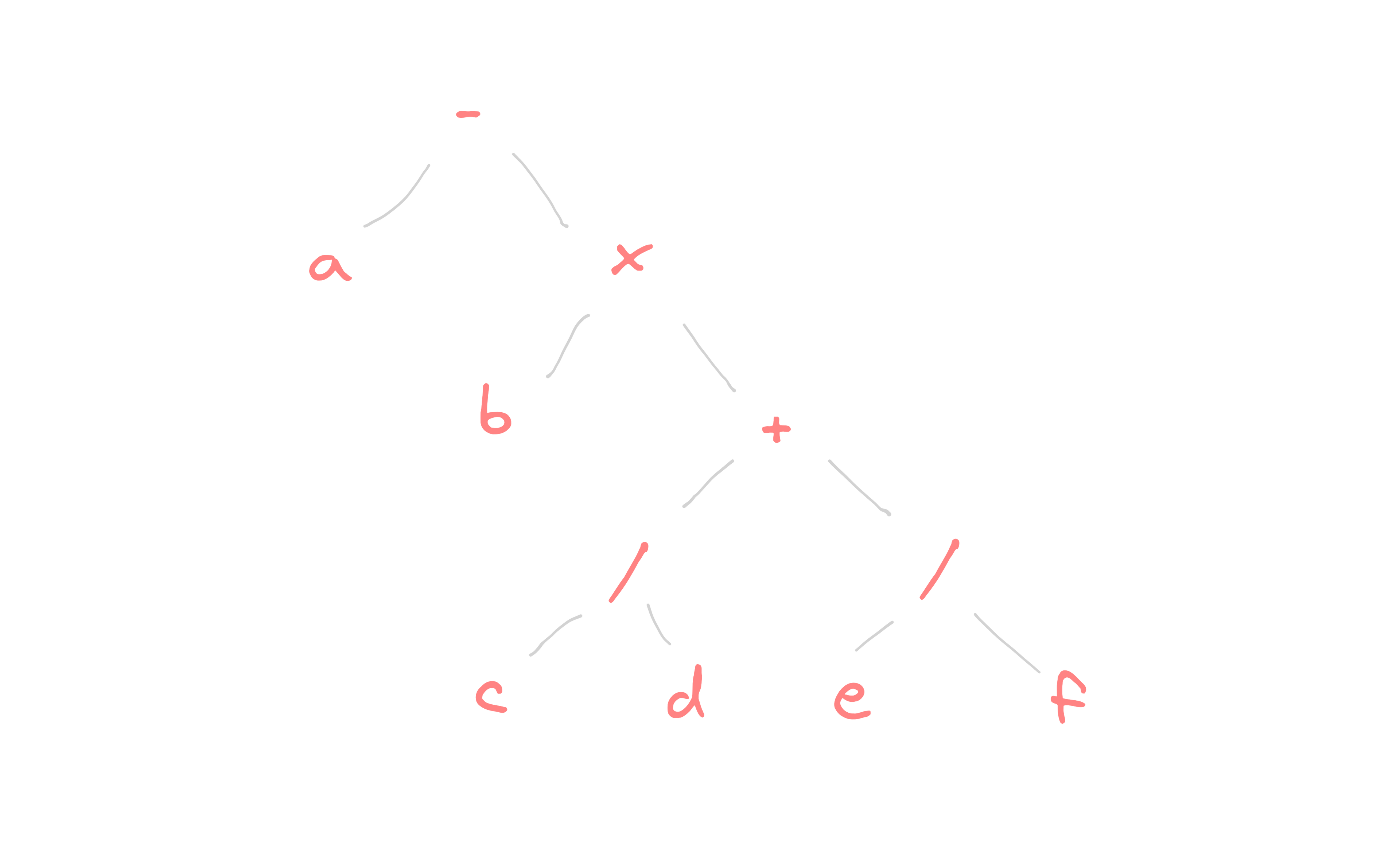
Trees are not only useful for representing hierarchical structures like family trees or sets. They can also be used to represent algebraic formulas. In this case, the nodes of the tree represent operations and the leaves represent operands. For example, the formula can be represented as the following tree:
Syntax trees are a way to show how a program is structured in programming languages. They use trees where each node represents a programming part, like a function call or a loop. The lines between the nodes show how these parts are related. Compilers and interpreters use syntax trees to analyze, understand, and process programs.
I appreciate the time you took to read my article on trees. Trees are fascinating data structures, and I am excited to delve deeper into the topic by exploring tree traversal algorithms and their implementations.
In my upcoming articles, I will be discussing different tree traversal algorithms, including depth-first search and breadth-first search, and how they can be used to perform various operations on trees. Additionally, I will be exploring different types of trees, such as AVL trees and red-black trees, and how they can be used to optimize search time and maintain balance in the tree structure.
I hope that my future articles will be informative and helpful for anyone interested in learning more about trees and their applications I look forward to sharing more with you soon.
Join my web development newsletter to receive the latest updates, tips, and trends directly in your inbox.
Related Articles
Implementing Heaps : A Comprehensive Guide
Learn how to create a min heap and their operations
Creating and traversing tries
Tries, also known as prefix trees, are tree-like data structures used for quick string searching.
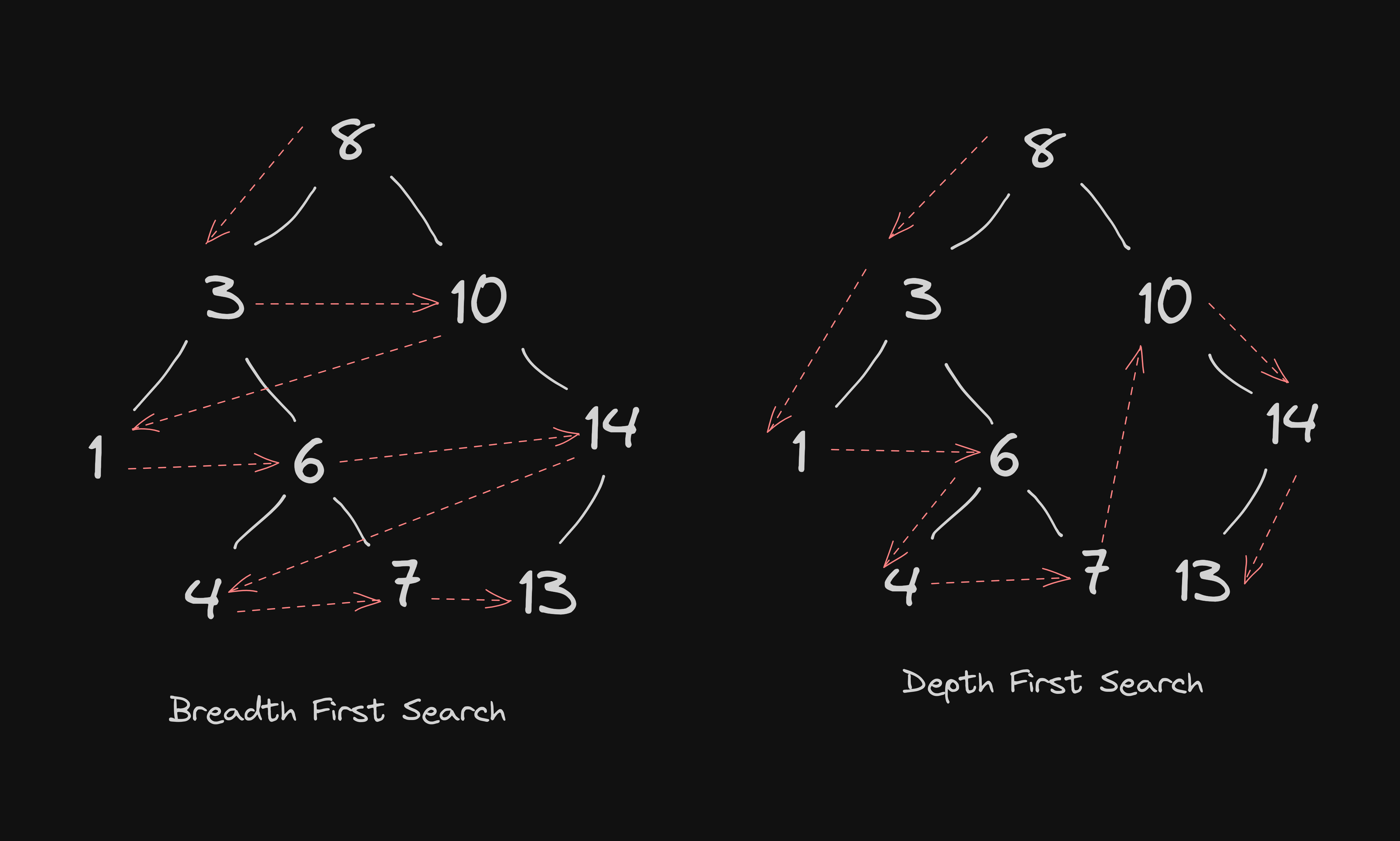
Exploring Tree Traversals: Depth-First Search and Breadth-First Search Algorithms
Take a deep dive into the world of tree traversal with this article, which covers both depth-first and breadth-first search algorithms.